I agree with much of the first part of this second video regarding factoring of code out into functions but I think it's important to really emphasize the caveat (as pointed out by John Carmack - on Jonathan Blow's site and covered in the video - we don't disagree here!) that this does not really apply to pure / referentially transparent functions.
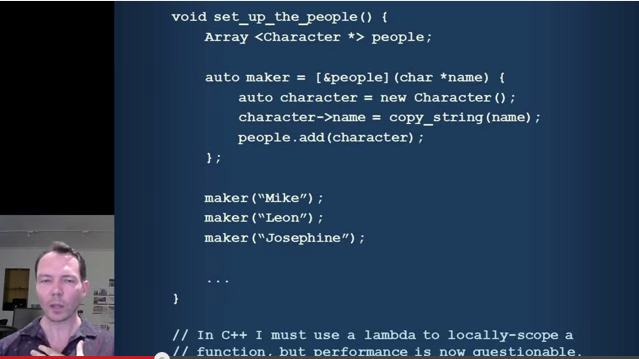
There's a section of the video here on the value of local blocks and lambdas for factoring functionality locally to a function when you don't want to pull it out into global scope yet. Again, I agree with most of this (this is one of the things I love lambdas for in C++11). I do just want to call out the factual error / misinformation included in passing here though that lambdas have unwanted overhead in C++ when used like this. Lambdas in C++ as used here (stored in an auto local stack variable) don't do any heap allocation unless as a side effect of capturing a variable by value that itself does heap allocation when copied. Possibly there's confusion with the case of storing a lambda in an std::function rather than as a local auto variable which might indeed cause heap allocation. Anyway, you don't have to worry about performance when using lambdas this way in C++.
It's also worth noting that extracting a local named lambda from inside a function to file scope does not require changing any syntax. Lambdas as global objects are perfectly valid. There's no need to switch back to function syntax for this refactoring. I think because lambdas are new and still a little unfamiliar to C++ programmers people don't always realize they are full first class citizens of the language now and you can do this.

There's a discussion next of variable definition syntax. I think the parallels to the arguments for C++ Almost Always Auto style declarations here are interesting. The consistency argument is basically the same. I'm somewhat agnostic on this syntax debate (although it seems to get some C++ programmers quite worked up) and I find in my own code I tend to use auto when I want type deduction and traditional 'type first' style when I want a specific type but if you want a syntax that gives you this kind of consistency today in C++ you can use it:
auto v0 = float{}; // v0 is a value initialized float with value 0.0f
auto v1 = float{1}; // v1 is a float with value 1.0f
auto v2 = 1; // v2 is an int with value 1
auto v3 = 1.0; // v3 is a double with value 1.0
auto v4 = 1.0f; // v4 is a float with value 1.0f
v4 = 1; // v4 is still a float, it's value is 1 converted to a float


Next comes a discussion of function definition syntax. Again the discussion focuses on syntactic consistency but if you want syntactic consistency you can have it today with C++14 (live version):
// a function (C++14 auto function return type deduction)
auto squareFunc(float x) { return x * x; };
// a function (C++11 explicit trailing return type)
auto squareFuncExplicitReturn(float x) -> float { return x * x; };
// a forward declaration for a function (C++11 trailing return type)
auto squareFuncForwardDeclared(float x) -> float;
// define previously forward declared function
auto squareFuncForwardDeclared(float x) -> float { return x * x; };
// a lambda with no capture (auto return type deduction)
auto squareLambda = [](float x) { return x * x; };
// a lambda with explicit trailing return
auto squareLambdaExplicitReturn = [](float x) -> float { return x * x; };
// an alias for a function pointer float -> float
using floatToFloat = auto (*)(float) -> float;
// a function that takes a function pointer float -> float,
// can take any of the above as a parameter
auto applyPtr(floatToFloat f, float x) { return f(x); }
// a C++14 generic lambda that applies any callable f to its argument x,
// we don't care about the exact types of f or x here, as long as
// they're compatible
// this is also optimally efficient (call to f() can usually be inlined)
auto applyLambda = [](auto f, auto x) { return f(x); };
Now true, C++14 has a number of ways to say the same thing and plenty of existing code using traditional style function signatures but if you want syntactic consistency for ease of refactoring nothing is stopping you from using this consistent style. Minor syntactic differences (the initial auto, type param rather than param: type) aside however, this syntax seems very close to what Jonathan proposes in the video and appears to satisfy most of the consistency / ease of refactoring goals he lays out.
It's worth calling out explicitly here that lambdas that do not capture can be implicitly converted to function pointers, which is why the captureless lambdas here can be freely passed to the applyPtr() function. You only need std::function if you don't know at compile time what kind of callable object you might be receiving or you don't want your function argument or struct member to be a template parameter (the generic lambda here effectively treats its f argument as a template parameter).
Jonathan doesn't talk here about how he'd implement the functionality of std::function. For performance reasons you really want to distinguish between the case of a callable of known type at compile time (when you can inline your call, often critical for performance, especially for higher order functions) from the more general case handled by std::function of an arbitrary callable object with potentially large captured state. You may be able to come up with syntax such that your compiler can do the optimal thing in all cases without the user being aware of the difference but it's not entirely trivial.
Happily we agree on "Anonymous functions ("lambdas") are not a big deal." and are a really great language feature. We also agree that lack of static typing in Scheme makes it unsuitable for large scale projects. I also agree with all the advantages Jonathan gives for his 'local block capture' language feature. All I'd point out here is that we can already have almost exactly this syntax in C++11!

So what does it take to turn this into valid C++11? We add 3 characters: ();! This calls the anonymous lambda we just defined.
Array<Character*> people;
[&people] {
auto character = new Character();
character->name = copy_string("Larry");
people.add(character);
}();
This is actually a technique I like and use in C++11, although I generally prefer to continue refactoring from here to a captureless function that takes parameters, and ideally one that returns a value rather than mutates its arguments.
Jonathan actually seems to intend somewhat different semantics from C++ for his capture clauses. In C++, you can still access globals inside a lambda without naming them in your capture, which this example actually does - copy_string is (presumably) a global function (or lambda!) and is not explicitly captured but is still referenced. He talks about capture clauses on functions at global scope though which restrict visibility for global variables, unlike C++ (what happened to lambdas not being a big deal? Do global functions and lambdas get special treatment here or do you need to capture them to reference them?). I think he perhaps slightly misunderstands C++ capture rules given his discussion of 'Double-bracket capture' as applying to globals.
The idea of restricting access to globals through 'capture clauses' is interesting. I'd certainly like to see compiler checked pure functions in C++ (no access to global state or calls to non-pure functions allowed - constexpr can give us something similar but not quite the same) but being able to gradually restrict access to globals as described here does seem like a potentially useful middle ground. I do wonder how workable the 'strict' version (which he denotes with [[]] double square brackets capture clauses) would be in practice though - it seems to risk similar problems to checked exception specifications in Java when it comes to calling other functions, with cascading captures rapidly getting out of hand. The related problem with const correctness Jonathan mentions seems a milder version of this (and I am a big fan of const correctness unlike Jonathan!) but perhaps it would be workable. As a side note - const is a very valuable tool for thread safety so I find Jonathan's position here (finding const not useful but wanting help with thread safety) a bit contradictory.
Finally in this video there's some discussion of global variables and excessive concern for safety in Rust. I think Jonathan underestimates the problems that global variables, mutable state and unrestricted pointer aliasing cause in C++ both for correctness and for performance but that's a big enough topic to be an article to itself, which I hope to write soon.