This post is one of a series of posts in response to Jonathan Blow's videos about a new programming language for games. See the introductory article for some background, disclaimers and links to other posts in the series. This post focuses on the first video in the series.
RAII
Jonathan spends quite a bit of time in his first video discussing RAII. I disagree with much of what he says in this part of the talk but I want to focus on how C++ already addresses the memory specific issues he talks about. I want to first quickly adress his claim that RAII is primarily necessary for dealing with exceptions though. This is really not true, as he implicitly acknowledges elsewhere in his videos. RAII is valuable any time you have more than one possible code path through a function which happens all the time irrespective of whether you have exceptions. In the third video when he introduces his language's delay construct he is dealing with the exact problem that RAII is intended to address and he even guarantees the same C++ behavior of destruction being in the reverse order of construction.
But you don't even really need multiple possible paths of execution to see the benefits of RAII. The 'owning pointer' syntax Jonathan introduces is a recognition of the value of types managing their own memory rather than making it all explicit in the code that uses them in the style of C.
During the RAII discussion, Jonathan praises Go's support for mutiple return values. If you want that model of error handling, or want multiple return values for some other reason, C++11 makes it pretty straightforward with std::tie(). It's a touch more verbose than the equivalent in a language with native multiple return value support but IMO not enough to justify a new core language feature.
Another alternative approach to return values for functions that may fail is std::optional which didn't quite make the C++14 standard but is likely to make it into a TS before C++17. I tend to think optional is a more promising approach to dealing with the return of functions that may fail since you can build something like Haskell's Maybe monad to cleanly deal with chaining operations that may fail.

Jonathan moves on to give a code example for his owning pointer notation. As he kind of acknowledges here, this is a bad example because in practice you should just use a string type. Maybe not std::string, depending on your needs, but I struggle to see the supposed benefit here over using an owning string type so I won't spend more time on this example.
His next example is a simple Mesh struct.

I find his next claim a little odd. He talks about how he frequently encounters a situation in code where he wants to create a simple struct like this, initialize some scalars and allocate some memory for arrays in the constructor, then in the destructor he wants to free any memory he allocated. To me this misses half (or perhaps most) of the point of constructors, which is to construct the object... In an example like this that presumably means filling those arrays with something meaningful. If you don't want to do that in your constructor, you really don't need one (or a destructor) in C++11 (as we'll see in code shortly) but if you do want to initialize your arrays with some actual data then you likely still want a constructor and in C++ you can have one. And if your initialization is suitably trivial, you can get away without a constructor in C++11 anyway thanks to aggregate initialization and std::initializer_list constructors on std::vector as illustrated in the code sample below.
Since the boilerplate of constructors and destructors in C++03 can be a source of 'friction' (to use Jonathan's term) when initially writing some code, let's look at one way you might write and use a class like this in C++11. No explicit constructors or destructors are defined here, but we have fully automatic memory management and access to simple aggregate initialization syntax. You may notice that we've changed the ownership semantics here by using a vector, we'll discuss that more below. This also addresses many of the issues raised a little later in the video around storing separate sizes for your arrays, etc. Jonathan does acknowledge the existence of this approach in C++ but dismisses it 'because templates'. There's a whole article (or series of articles) that could be written around that but let me just say I want some harder evidence that the problems with templates are really as bad as their detractors claim with modern compilers and libraries (and especially with modules - you can try an early version out in clang right now!) before I'm going to be persuaded we need to jump ship to an entirely new language and tool chain.
The following discussion strikes me as even stranger. After railing against RAII, he now goes on to discuss how your debugger can help you find all the problems RAII is designed to statically prevent (double frees, use after frees, assigning something that's not meant to be assigned), but with this one particular type of ownership semantics baked into the language syntax the compiler can perhaps statically detect invalid usage. But this is exactly what C++ RAII objects give you at compile time! If you try and copy a unique_ptr, you'll get a compile time error. If you try and copy a shared_ptr you'll get a bumped reference count. If you try and copy a vector you'll get a copy of the contents. All these models of ownership are valid and useful in different situations and C++ gives you ways to express all of them in the standard library. If you have some other ownership model you want to express, you can build a new RAII class (or better yet, find one someone else has already built and tested) to do it for you.
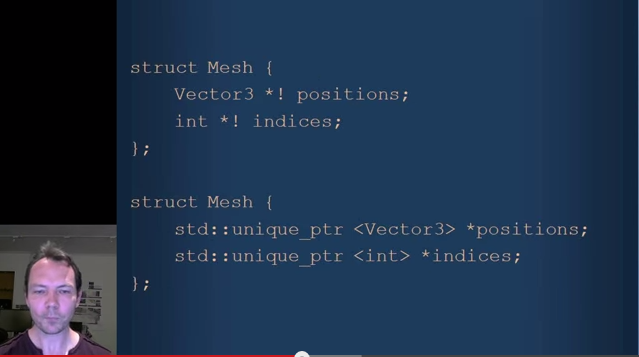
The next slide and accompanying discussion to me highlighted what's being missed in this whole section of the presentation - the existence of multiple valid ownership models. Jonathan says that a C++ fan would say C++ has unique_ptr for this (let's skip discussion that the slide has the syntax wrong - the C++ equivalent would be unique_ptr<Vector3[]> positions; - I think Jonathan does have some valid points about syntax and this mistake probably supports them).
Well actually, that wasn't my first thought. My first thought was 'we have vector for this' (or possibly dynarray which didn't quite make the C++14 standard). Or maybe even shared_ptr (though that wouldn't be my first choice). It depends on what ownership semantics you want your Mesh to represent. To me, that's not an inconvenient detail that C++ forces you to deal with, it's a fundamental design decision. Do you want your Mesh to act like a value type? To copy its positions and indices when you make a copy of it? Or do you want it to act with shared_ptr like ownership semantics and have copies refer to shared position and index arrays? I'd argue that most of the memory related bugs we see in C++ are due to confusion over which ownership model is being used for data and being clear about it up front will avoid most of those bugs ever happening.
The points about template instantiation error messages and build times when using the standard library are not entirely without merit but there are serious efforts underway to address both concerns. We've already seen clang make great strides on improving error messages and Concepts Lite will help a lot here. Modules will be a big part of addressing the build time concerns.
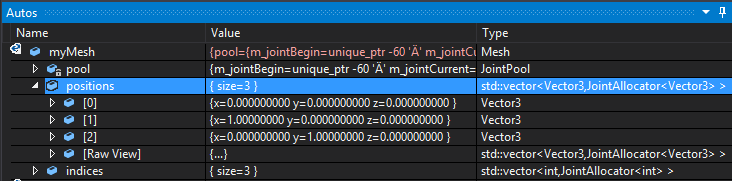
As mentioned earlier, I really want to see some better evidence from people who claim that the costs of templates don't justify the benefits because for all the times I hear this claim repeated I've seen very little in the way of numbers to back it up. Given that there are other casual claims made in the video that are based on very outdated information I would like to see some better evidence before dismissing templates out of hand. For example, the Visual Studio debugger has been able to show you the contents of a vector in the watch window perfectly clearly for several years now (see the screenshot below), along with most of the other STL container types and you can create your own Natvis visualizations for custom types. To the extent that these concerns are tooling / quality of implementation issues rather than fundamental language issues I'd also question why we don't focus on making better tools for C++ rather than starting over from scratch.
So about the syntax issue. Perhaps if we only had one ownership model to worry about, having built in syntax could be clearer. I think it gets less clear when you start considering multiple possible ownership models, some of which may be user defined. Saying unique_ptr<int[]> implies different ownership semantics to vector<int> or to shared_ptr<int[]> (that last one for a shared_ptr to an array is not yet standardized but is likely to make it into a TR soon). Saying vector<int> implies different usage semantics to dynarray<int> (whether you expect to ever change the sizes of an Mesh object's position and index arrays). These are fundamental concerns and I think it is important that our langague and libraries give us a good way to express them. I'm not sold that the solutions proposed in the video are an improvement to what we already have in C++.
The next part of the video talks a bit more about some of the common memory related errors in C and C++ and how they're not that big a deal if you have good support for catching them from your debugger and debug heap. While I'd agree that certain common types of memory errors are not usually a huge deal to find and fix and probably not our biggest problem (although delayed or asynchronous use after free memory stomps can still be a big pain to track down even with good debugging support from your environment), I'd still much prefer a world where they're really difficult to introduce. I'd argue that modern C++ already gives us that world, while still leaving an escape hatch to do unsafe things if you really feel you need it. We can already write clean, simple, efficient code in C++ that avoids us ever having to deal with those kinds of memory errors. I'd prefer working with that style of code than with the style proposed here.
The video moves on to make a somewhat confusing (to me) claim about how C++ conflates allocation and construction. C++ does separate these concerns however. You might not love the native language syntax for it (placement new and explicit destructor calls and the admittedly slightly confusing fact that the operator new and operator delete functions you implement to control allocation share a name with the new and delete operators responsible for calling them and invoking the constructor/destructor) but the whole library of standard containers is built on the (much improved for C++11) allocator model and it is quite possible to use it with your own types and avoid ever dealing directly with new and delete unless you're actually implementing an allocator.
Ironically, one of the other primary ideas behind RAII is to isolate / separate out memory management (or other resource management) concerns from client classes that use those resources. This is why the Mesh example above can get away without any explicit constructor or destructor and still manage memory correctly - memory management is delegated to the contained vector members leaving the Mesh class only concerned with initialization of those vectors and not managing their memory.
Custom allocation
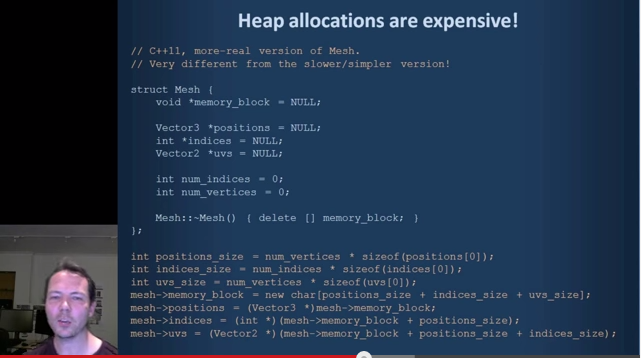
The next section of the video moves on to discuss 'joint allocation'. C++11 allocators are the solution to this problem too. The code above is probably not how you should write this 'jointly allocated' Mesh class in C++11. I just want to preface this by saying applying this technique at all is probably premature optimization unless you've actually profiled and identified a performance concern with the Mesh class, but let's assume you have for the sake of this discussion. So here's one way you might write this in C++11 (ideone link includes the supporting allocator code enabling the usage illustrated below).
Now admittedly the struct definition is not quite as clean now as the example in Jonathan's proposed language syntax but I don't think it's too horrendous. It's probably possible to do a bit better than this with more thought put into the joint allocator design and the additional code overhead to support joint allocation is likely to be less of an issue in a more complex real world struct anyway. This is just one of many custom allocation schemes you might want to implement (a real game probably has linear / stack allocators, stomp allocators, pooled allocators, debug allocators and more) and C++11 gives you full control as a user over that. Jonathan hasn't spoken much yet about how he would support arbitrary custom allocation schemes but it's likely to involve additional complexity over the best case syntax he presents here for joint allocation.
While I think it's important to provide the full code for how the allocator is implemented to show how you can implement Mesh with custom joint allocation, I don't want to go over the details of the implementation here as it's not the focus of the current discussion. I will acknowledge that the custom allocator code is not itself terribly elegant or simple (and it may well have bugs - it was hacked together quickly for the example). In a real game development scenario though this would be library code, written once and used in many different situations (and would have to get a bit more complicated to handle things like alignment correctly but since Jonathan skipped those details in his example for the sake of exposition I have too). I would be surprised if it was more complicated than the code required to implement joint allocation in the compiler for a new language which is what the allocator code should be viewed in comparision to.
I do want to highlight a couple of details of the implementation. One thing to note is that JointVector here is not a custom type, it is simply an alias template for std::vector with my custom JointAllocator allocator. This means that you can use this technique with any standard library container, or any third party container that supports the standard allocator model. The way I've implemented this currently, you'd need to specialize the JointPoolSizeTraits template for each container type you wanted to support to allow it to calculate in advance how much memory would be required for n elements of a particular type and this would require some implementation specific information (most standard library container implementations, even std::vector, perform some extra allocations of types other than the contained type). There are probably other / better ways you might implement a library to support this model.
There are language features that would make custom allocation schemes like this simpler for the end user to apply in their classes - reflection for example would simplify use of the JointPool here - but you can already get a pretty long way to a nice end user experience for custom allocation with the improved C++11 style allocator model and allocator_traits and the huge boon of alias templates to make it easy to define your own short names for templated containers with custom allocators.
Jonathan goes on to talk about the possibility of the compiler merging allocations itself. This is an interesting idea but I'm not sure how feasible it is in practice. If it is feasible, C++14 allows for it (I had to ask to find this out!), although in practice there is something to be said for the argument that the compiler has more visibility into the semantics of the allocations if support is built into the language than when they are wrapped via custom RAII types. I'd say the jury's out on this though absent an implementation that demonstrates the ability to do this together with an argument for why it wouldn't be feasible in C++. The fact that this language was explicitly added for C++14 suggests to me that at least one compiler wanted to implement it.
The next part of the video discusses the application of the joint allocation to string types (of course the JointAllocator example I give above is trivially extended to support std::string members) along with some other memory related optimizations. As Jonathan points out, it's perfectly possible to make a string type that implements some of the additional optimizations he describes (I've seen them in use). I think it's a little disingenuous to dismiss such implementations as "probably totally crazy balls". There's plenty of production code that implements these kinds of systems and again, we should be comparing the library implementation of such facilities to the implementation of a custom compiler that performs these optimizations.
Jonathan rightly points out on a number of occasions that implementing a compiler is not such an impossible task for a competent programmer. He seems to think that implementing good C++ libraries is somehow a much more difficult task however. I disagree with him on that second part - I think a programmer capable of implementing a compiler with the sort of functionality he is describing in his videos is probably perfectly capable of implementing many of the same sorts of features in a C++ library. Depending on the particular problem being solved, one or the other approach may be simpler to implement or be more usable for end users but writing a useful C++ library seems a more tractable, modular and approachable task to me than designing a new language and implementing a new compiler for it, or even than designing and integrating a new language feature to an existing compiler.

Jonathan next claims the ideas he's been discussing are "the type of thing hardly anyone in language design is thinking about". I think we've demonstrated already here that the C++ committee are thinking about these kinds of things both at the language and library design level. They're also actively soliciting input from the game development community! The new C++11 allocator model, the new C++14 wording on coalescing allocations, the string_view proposal and many more accepted and propsed C++ language and library features address exactly these kinds of things!
Other stuff
Let's skip through a few other issues raised quickly:
- "no god damn header files" - agreed, again see Modules
- "Refactorability": see the work that clang/LLVM is doing to make it easier to build automated refactoring tools for C++ (I'll address some specific points further in a future post, but dismissing the existing solution to the specific problem mentioned of using references is unconvincing)
- "Optional Types": again, see
std::optional - "Concurrency": see the massive amount of work coming out of the Concurrency Study Group SG1, this is by no means a unique problem to games
- "implicit type conversions": see uniform initialization syntax (no narrowing conversions), crank up your compiler warning level, use static analysis tools
- "named argument passing": A proposal for named arguments for C++
- "Can introspect and serialize": see the work coming out of the Reflection Study Group SG7
- "The program specifies how to build it.": Ok, I'll give him this one :) All compilers I know of can already accept multiple .cpp files as arguments to one invocation though!
- "permissive license": is there a specific thing he doesn't like about the clang/LLVM license?
- Sized integer types: cstdint header.
- "Nested comments": I'm not sure if there's a good reason this isn't supported, you can always submit a proposal.
- "a better preprocessor": C++11 gave us constexpr for compile time function evaluation and C++14 generalized it. There's very few remaining situations in C++ where you need the preprocessor, other than
#includeand stringizing / token pasting.